Automatically Evaluate Your Chatbot with Conversation Scenarios
Design multi-turn conversation scenarios visually, execute them automatically, and get quantitative evaluation scores. No code required.
What Changes with ConvoProbe
Before
Manually testing conversations one by one, missing edge cases
After
Visual scenario design covers all conversation paths systematically
Before
"Seems fine" — evaluation based on gut feeling
After
Quantitative scores with semantic match, accuracy, and consistency metrics
Before
No idea if prompt changes improved or degraded quality
After
Before/after comparison with reproducible scenario execution
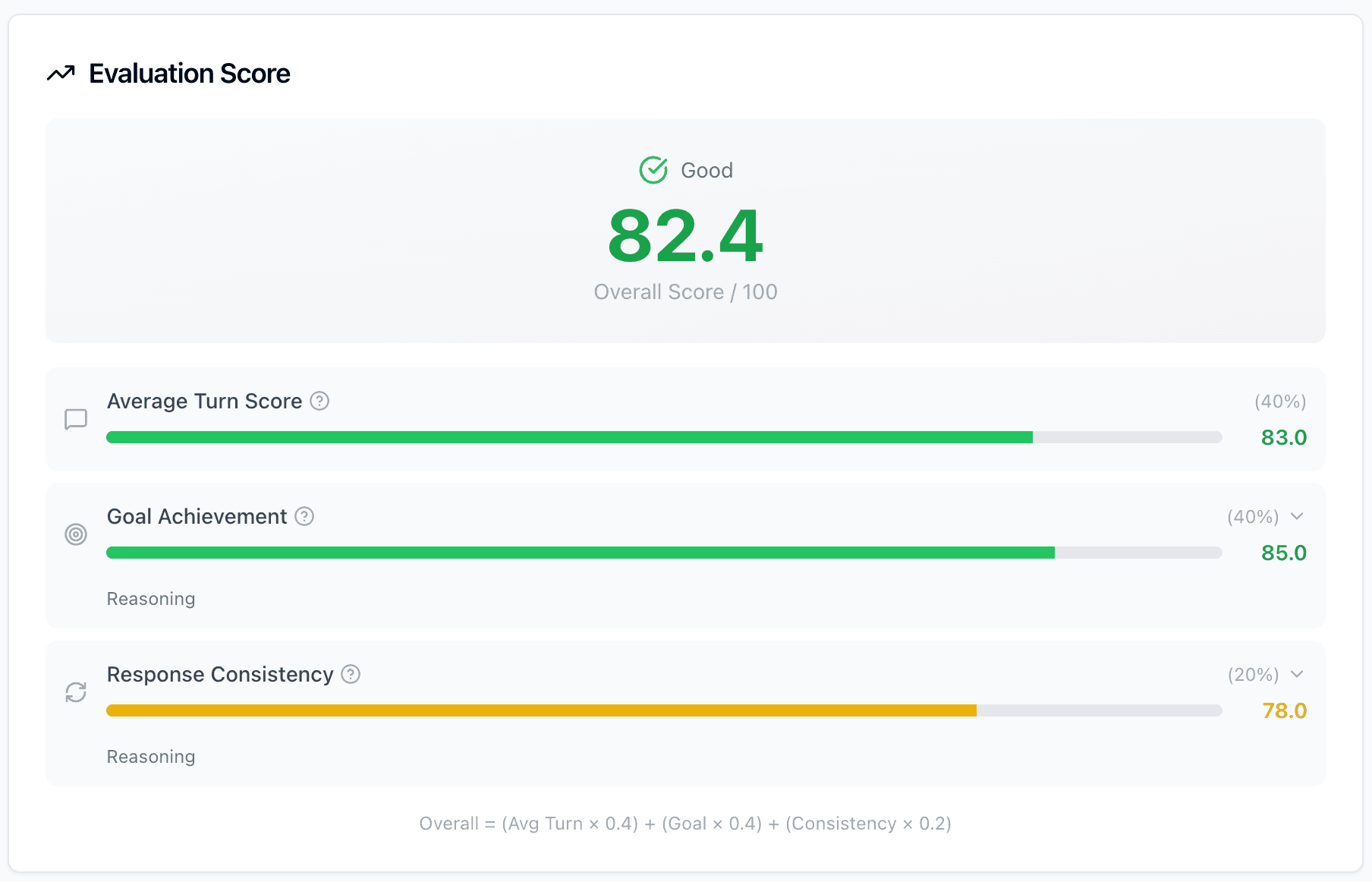
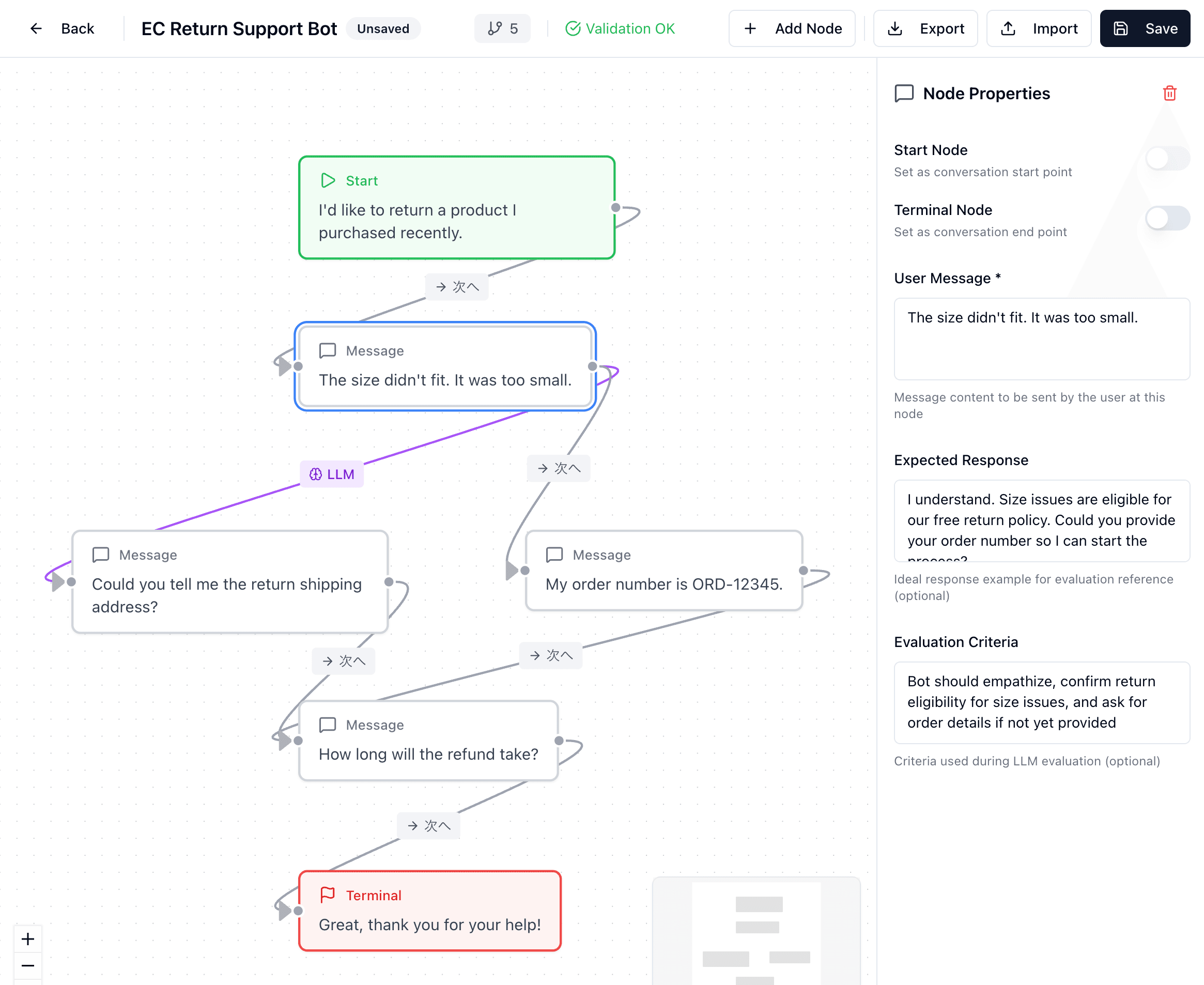
Key Features
Everything you need to evaluate multi-turn chatbot conversations
Visual Scenario Design
Design branching conversation flows with a drag-and-drop editor. Define user messages, expected responses, and LLM-based conditional branches.
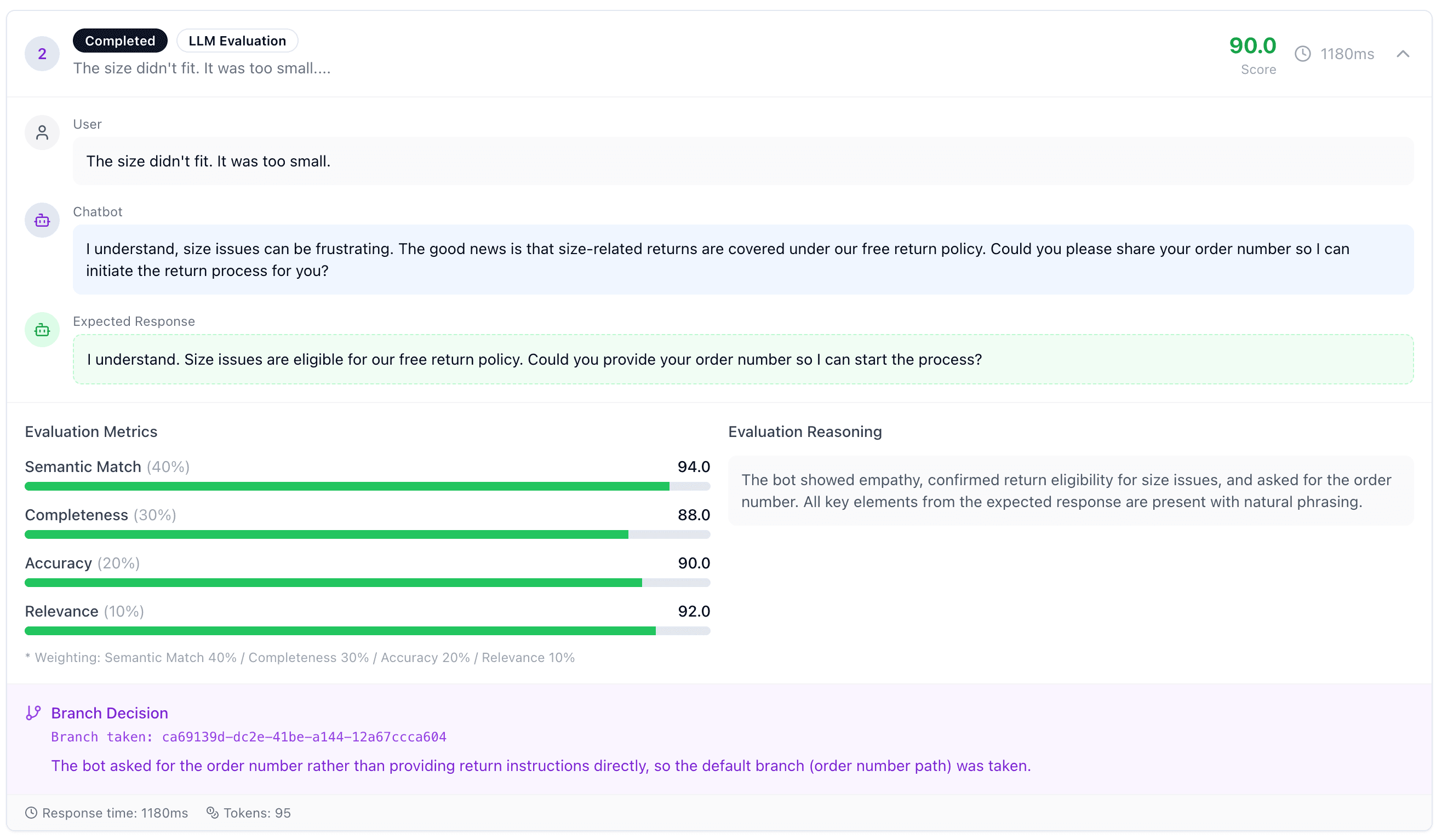
Automated Evaluation
Execute scenarios automatically and get scored results. Semantic match, goal achievement, and response consistency — all measured quantitatively.
No Code Required
Built for product managers and QA teams, not just developers. Design, execute, and review evaluations entirely through the UI.
Beyond Observability
Tracing & Monitoring
What happened?
Post-hoc analysis of production logs and traces. Essential for debugging, but reactive by nature.
Langfuse, LangSmith, Opik, Arize...
ConvoProbe
Is it good enough?
Proactive pre-deployment testing with designed scenarios. Know your chatbot's quality before users encounter issues.
ConvoProbe Is For You If...
You're building or managing a Dify-powered chatbot
You want to test conversation quality before deploying prompt changes
You need quantitative metrics, not just subjective impressions
You want to cover edge cases in multi-turn conversations systematically
You need a tool that non-engineers can use for QA